Oracle Optimizer 관점에서 알아보는 Hash Join의 SQL 성능 저하 원인
1. Preface
(프로시저는 실제로 동작하지만 프로시저 동작 환경은 실제가 아닌 설정된 가상의 환경입니다.)
면접자 중 합격자를 정식 회사원으로 데이터베이스에 등록하기 위하여 작성한 프로시저를 실행하여 검사하던 중 프로시저의 동작이 완료되지 않고 멈춘 상태로 어떤 오류인지, 어디서 발생하는 오류인지 확인할 수도 없는 상황이 되어버려 곤란한 상황에 놓이게 되었습니다.
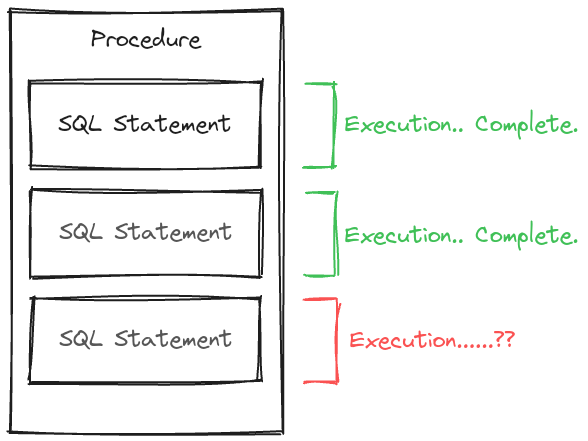
그렇더라도 문제는 해결해야겠죠.
프로시저에 작성된 SQL 구문를 하나하나 실행시키며 문제를 일으키는 SQL 구문을 몇 개 찾아낼 수 있었습니다.
1
2
3
4
5
6
7
8
9
10
11
MERGE /*+ USE_HASH(tab1 tab2)*/
INTO emp tab1
USING (
SELECT a.identify_code, a.serial_number, b.hiredate
FROM emp a, cnd b
WHERE a.serial_number = b.serial_number
AND b.serial_number IN (SELECT serial_number FROM pass_list)
) tab2
ON (tab1.serial_number = tab2.serial_number AND tab1.identify_code = tab2. identify_code)
WHEN MATCHED THEN
UPDATE SET tab1.hiredate = tab2.hiredate;
겉보기에는 문제가 없어보이는 SQL 구문인데 어떤 부분이 문제를 일으킨걸까요?
우선 MERGE문 자체에는 이상이 없는 것으로 보입니다.
처음보는 /*+ USE_HASH(tab1, tab2) */ 라는 구문이 문제를 일으킨걸까요?
해당 구문을 지우고 SQL 구문을 실행시켜보니 이전과는 다르게 단숨에 쿼리가 실행 완료되었습니다.
초면인 USE_HASH 구문을 구글링 해보니 Oracle SQL 튜닝 기법 중 하나인 Hash Join Hint라고 합니다. 그렇다면 Hash Join, Join Hint는 무엇이며, SQL 튜닝 기법이라면 어째서 성능을 저하시킨걸까요?
이제, Hash Join Hint가 일으킨 SQL 구문의 성능 저하의 원인을 SQL Processing 절차 속 Oracle Optimizer의 관점으로 살펴봅시다.
2. SQL Processing
SQL 구문은 다음과 같은 절차를 통해 실행됩니다.
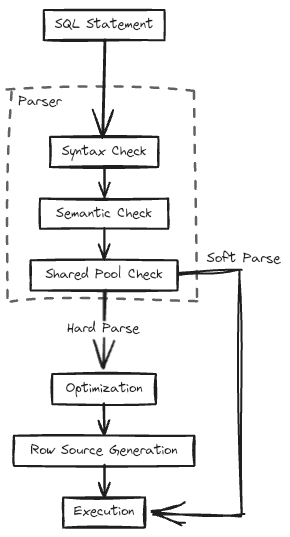
- SQL Parsing
- Optimization
- Row Source Generation
그럼 각 단계에 대해서 살펴보도록 합시다.
2-1. SQL Parsing
Parsing 단계에서는 사용자의 SQL 구문의 실행이 요청되면, SQL 구문을 분석하고, 커서를 열어 확인된 구문을 저장하고 해당 구문의 리소스 스킵을 결정하기 위해 parse call이 발생합니다.
SQL Parsing에서는 세 가지의 구문 확인이 진행됩니다.
- Syntax Check
수행하려는 SQL 구문 중 작성 규칙에 어긋나는 구문 자체의 오류 확인, 예를 들어 오타가 없는지를 확인 - Sementic CHeck
수행하려는 SQL 구문의 논리적 오류 확인, 예를 들어 대상으로 하는 테이블, 컬럼 등이 실제로 존재하는가를 확인 - Shared Pool Check
SQL 구문 중 구문 수행 시 해당 SQL의 수행으로 발생하는 리소스를 스킵할 수 있는가에 집중
Shared Pool Check
Oracle Database는 모든 SQL 구문을 해싱 알고리즘을 통해 해시화하여 해싱된 모든 값을 Shared Pool의 Shared SQL Area에 저장합니다. 이렇게 저장된 SQL ID는 동일 버전의 DB라면 서로 다른 인스턴스에서도 해당 ID를 동일하게 사용됩니다.
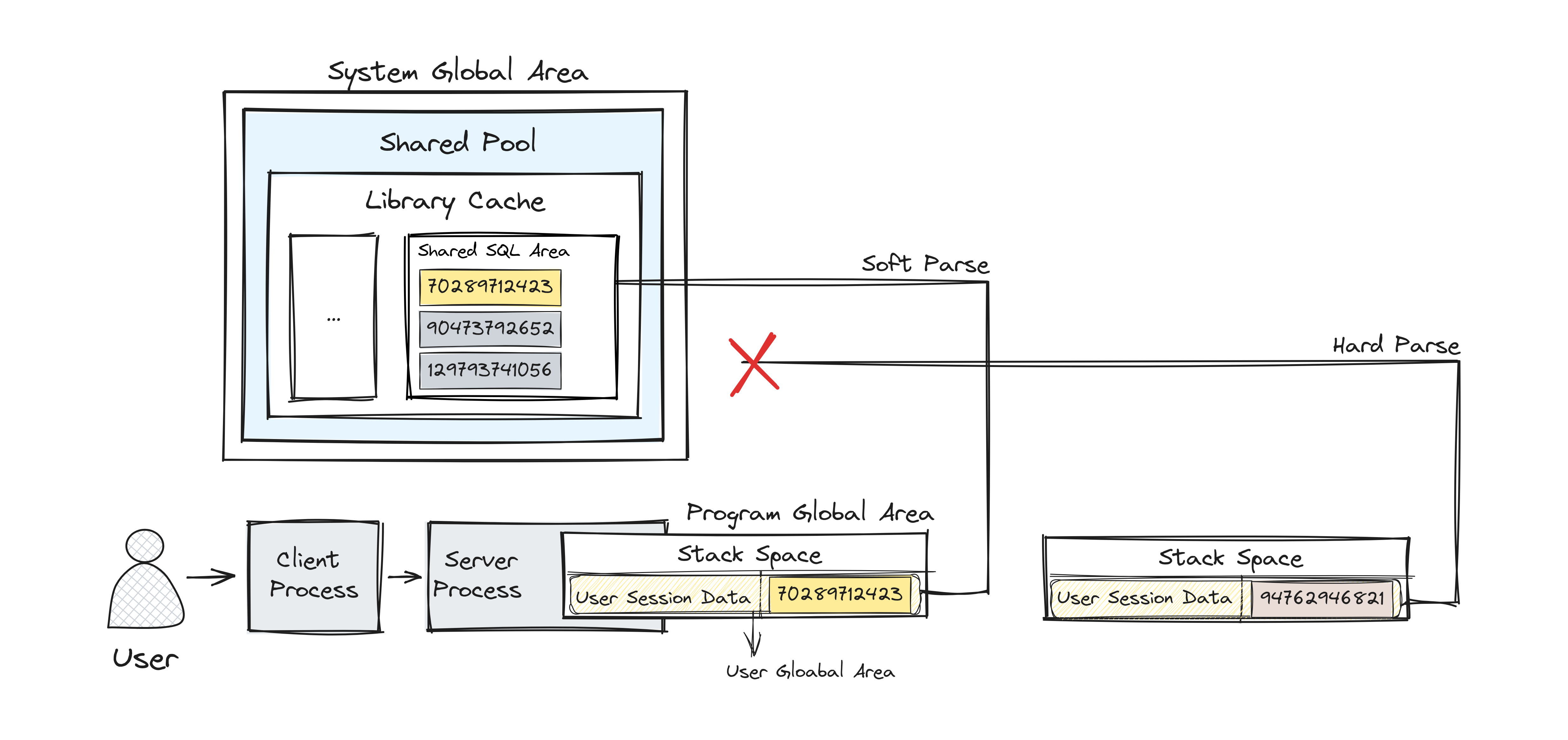
Shared Pool Check의 결과는 Shared SQL Area의 타겟이 되는 SQL ID의 유무에 따라 다음과 같이 나뉘게 됩니다.
- Soft Parse (Library Cache Hit) 실행하려는 SQL 구문의 ID가 존재하여 Shared Pool Check가 성공했을 경우 해당 구문을 실행하는데 사용되는 리소스를 스킵합니다.
- Hard Parse (Library Cache Miss) 실행하려는 SQL 구문의 Shared Pool Check에 실패하여 이후의 과정을 수행하여 SQL 구문을 실행해야 합니다.
문제의 SQL은 Hard Parsing 되었을테니 남은 프로세싱 과정을 살펴봅시다.
2-2. Optimization
Oracle Optimizer는 SQL 구조, 사용 가능한 통계 정보, 모든 관련 최적화 프로그램 및 실행 기능을 기반으로 SQL 문에 대해 가장 효율적인 실행 계획을 결정합니다.
Optimizer는 SQL 구문에 대하여 최적의 접근 방식과 목표를 계획할 때 다음 세 가지 사항을 고려합니다.
- Initialization Parameter
- CBO Statistics in the Data Dictionary
- Optimizer SQL Hints for Changing the CBO goal

드디어 최종적으로 알아보고자 하는 SQL Hint가 CBO라는 Optimizer의 고려 사항 중 하나라는 것을 알게 되었습니다. Optimizer에 대해 조금 더 구체적으로 알아볼까요?
Initialization Parameter
Initialization Parameter는 Optimizer 동작의 다양한 측면에 영향을 주는 초기화 매개변수입니다.
초기화 매개변수 중 특히 OPTIMIZER_MODE라는 매개변수는 말 그대로 Optimizer가 어떤 방식을 채택할 것인지를 선택합니다.
- CHOOSE: 엑세스 테이블에 대한 Data Dictionary의 통계 정보를 바탕으로 CBO와 RBO 중 하나를 선택
- ALL_ROWS: 통계 정보 유무에 관계없이 액세스 테이블의 모든 로우에 대해 최적화를 위한 CBO 선택
- FIRST_ROWS_
n: 통계 정보 유무에 관계없이 액세스 테이블의 n개 로우에 대해 최적화를 위한 CBO 선택 - FIRST_ROWS: 처음 몇 개의 로우에 대해 최적화를 위한 CBO 선택
- RULE: 통계 정보 유무에 관계없이 RBO 선택
1
2
3
4
5
6
SQL> ALTER SESSION SET OPTIMIZER_MODE = (CHOOSE, ALL_ROWS, FIRST_ROWS_1, RULE);
SQL> SHOW PARAMETER OPTIMIZER_MODE
NAME TYPE VALUE
------------------- ----------- ----------
optimizer_mode string choose
OPTIMIZER_MODE을 통해 Optimizer의 작동 방식은 RBO, CBO 두 가지 방식으로 나뉜다는 것을 알게 되었습니다.
RBO(Rule-Based Optimizer)
RBO는 15개의 정해진 우선 순위 규칙에 따라 접근 경로를 설정하는 방식의 Optimizer입니다.
하지만 RBO는 Oracle 11g 이후로 지원을 중단했을 뿐만 아니라, 확인해보고자 하는 목표는 RBO와 거리가 멀기 때문에 구체적으로 다루지 않겠습니다.
CBO(Cost-Based Optimizer)
후에 살펴보겠지만 Hash Join에 대해 간략하게 설명하자면, Hash Join은 두 테이블 간의 조인 시 두 테이블 중 선택된 하나의 테이블을 해시 영역에 올리고 남은 하나의 테이블을 스캔하며 해시 테이블과 조인하는 조인 방식입니다. 이때, Hash Join이 수행되기 위해서는 CBO의 사용이 요구되어집니다.

점점 문제의 SQL 구문 및 Hash Join에 관해 가까워지고 있는 기분이 듭니다.
문제를 분석하기 위한 마지막 단계인 Optimizer의 실행 계획 선택 과정에 대해 조금 더 알아보도록 합시다.
CBO는 Data Dictionary의 통계 정보를 바탕으로 비용을 계산하여 최적의 접근 경로를 설정하는 Optimizer입니다.
CBO는 다음과 같은 절차로 가장 효율적인 실행 계획을 선택합니다.
- 사용 가능한 액세스 경로와 힌트를 기반으로 잠재적인 계획 집합을 생성
- Data Dictionary의 통계(I/O, CPU, memory와 같은 컴퓨터 리소스)를 기반으로 액세스 경로 및 조인 순서의 비용을 계산
- 계획의 비용을 비교하고 가장 낮은 비용의 계획을 선택
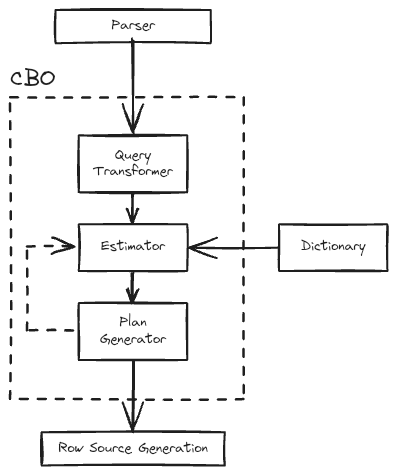
앞서 설명한 절차를 바탕으로 CBO의 구성요소에 대해 알아보겠습니다.
1. Query Transformer
원본 SQL 문을 더 낮은 비용으로 의미상 동일한 SQL 문으로 다시 작성하는 것이 유리한지 여부를 결정합니다. OR 확장, 뷰 머징, 서브쿼리 중첩 해제 등의 방법을 사용하여 쿼리를 재작성합니다.
![]()
2. Estimator
주어진 SQL 구문에 대하여 세 가지의 측정값(Selectivity, Cardinality, Cost)을 사용하여 실행 계획의 전체 비용을 결정합니다.

Selectivity 테이블의 행 집합에서 특정 수의 행을 필터링하여 조건을 통과하는 행 수에 관한 값
0.0 ~ 1.0 사이 값을 가지며 0.0이면 행이 선택되지 않았으며 조건절이 더 선택적이라는 뜻Cardinality 실행 계획의 각 작업에서 반환되는 row 수의 추정치 Cardinality는 실행 계획의 모든 측면(조인 비용, 정렬 비용 등)에 영향을 미치므로 매우 정확해야 함
Cost Cardinality 및 Data Dictionary의 통계(I/O, CPU, memory와 같은 컴퓨터 리소스)를 기반으로 액세스 경로 및 조인 순서의 비용을 계산.
3. Plan Generator
위에서 계산한 비용을 바탕으로 다양한 액세스 경로, 조인 방법 및 조인 순서를 시도하여 다양한 계획을 탐색하고 가장 비용이 낮은 계획을 선택하게 됩니다.
2-3. Row Source Generation
앞선 과정을 모두 거쳐 선정된 실행 계획을 받아 실제로 실행 가능한 코드의 형태로 다시 포맷팅하는 작업을 수행합니다. 수행 가능한 형태로 다시 생성된 계획은 각 단계별로 수행되며, 각 단계는 row set을 반환하 이는 후에 SQL plan을 살펴볼 때 나오는 row source tree와 관련이 있습니다.
3. Explain Plan
드디어 앞서 살펴봤던 Hash join이 문제를 발생시킨 SQL 구문의 실행 계획을 해석하기 위한 기초 지식을 쌓았습니다.
마지막으로 SQL 문제의 주요 원인인 Hash Join이 무엇인가에 대해까지 마지막으로 알아보고 실행 계획을 살펴보도록 하겠습니다.
3-1. Hash Join
Hash Join은 두 테이블 중 더 작은 테이블(Build Table)을 해시 테이블로 만들어 메모리에 올린 후, 더 큰 테이블(Probe Table)을 해시 테이블과 조인 컬럼을 기준으로 매핑시키는 조인 방식입니다.
이 과정에서 해시 테이블은 PGA 영역에 올라가 latching 없이 두 테이블 간 데이터 액세스 및 조인이 가능하므로 대용량 테이블 조인에서 강점을 가집니다.
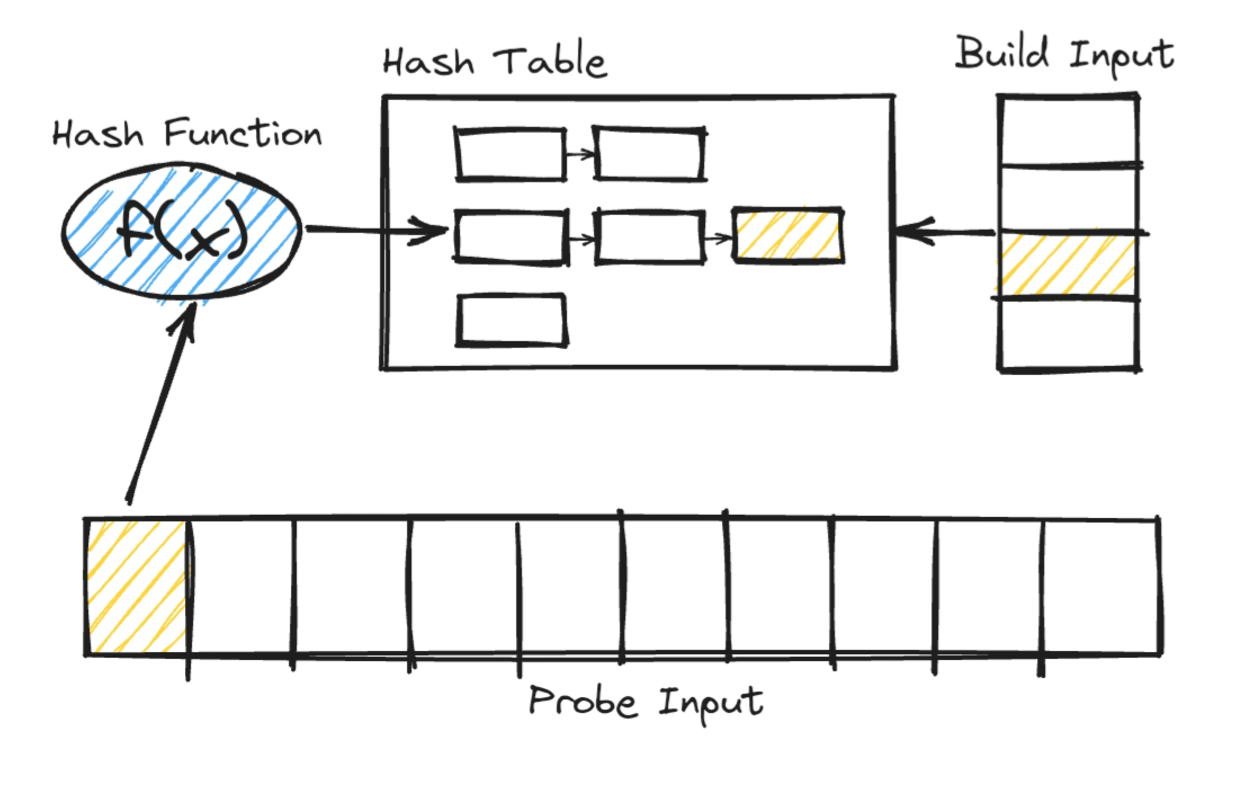
Hash Join의 개념을 수행 절차를 통해 순서대로 살펴보면,
- Build Table을 풀 스캔한 후 각 행의 조인 컬럼을 해시 함수를 통해 해시 값으로 만들어 PGA 영역에 해시 테이블을 만듭니다.
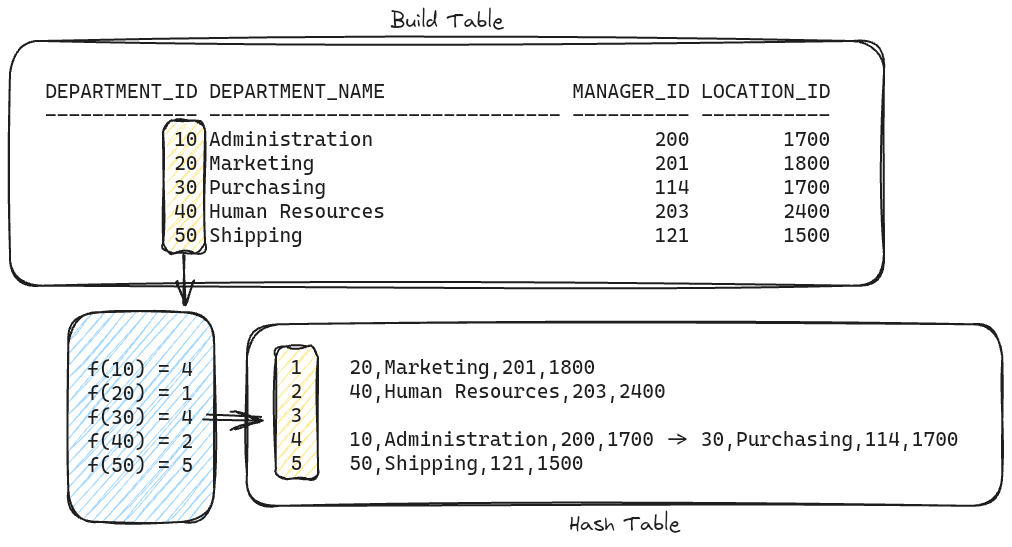
- Probe Table을 최소 비용이 사용되는 방식으로 풀 스캔한 후 검색된 각 행에 대해 다음 조인 절차를 수행합니다.
- Probe Table의 동일한 조인 컬럼에 해시 함수를 사용합니다.
- 해시 테이블에 동일한 값을 가지는 조인 컬럼 슬롯에 대하여 동일한 행이 존재하는지 확인합니다.
- 두 개 이상 존재한다면 linked된 각 행을 체크하여 동일한 행을 찾아내고, 하나만 존재한다면 찾은 행을 전달합니다.
Hash 조인 절차를 수행하기 위해서는 두 개의 테이블 중 한 테이블이 크기가 작은 집합이어야 하며 동등 비교 연산자로 비교되는 equi join 이어야 합니다
Hash Join을 위한 Build Table의 크기가 크다면 PGA 영역에 해시 테이블을 빌드하여 조인하는 In-Memory 방식이 불가능한 경우도 있습니다. 이 때는 해시 테이블 중 일부 파티션을 만들어 디스크의 임시 공간을 사용합니다.
3-2. Explain Plan
드디어 실행 계획을 분석하기 위한 모든 사전 준비를 마쳤습니다. Hash Join Hint가 어떤 문제를 일으켰는지 실행 계획을 하나씩 뜯어보며 알아내보도록 합시다.
1
2
3
4
5
6
7
8
9
10
11
MERGE /*+ USE_HASH(tab1 tab2)*/
INTO emp tab1
USING (
SELECT a.identify_code, a.serial_number, b.hiredate
FROM emp a, cnd b
WHERE a.serial_number = b.serial_number
AND b.serial_number IN (SELECT serial_number FROM pass_list)
) tab2
ON (tab1.serial_number = tab2.serial_number AND tab1.identify_code = tab2.identify_code)
WHEN MATCHED THEN
UPDATE SET tab1.hiredate = tab2.hiredate;
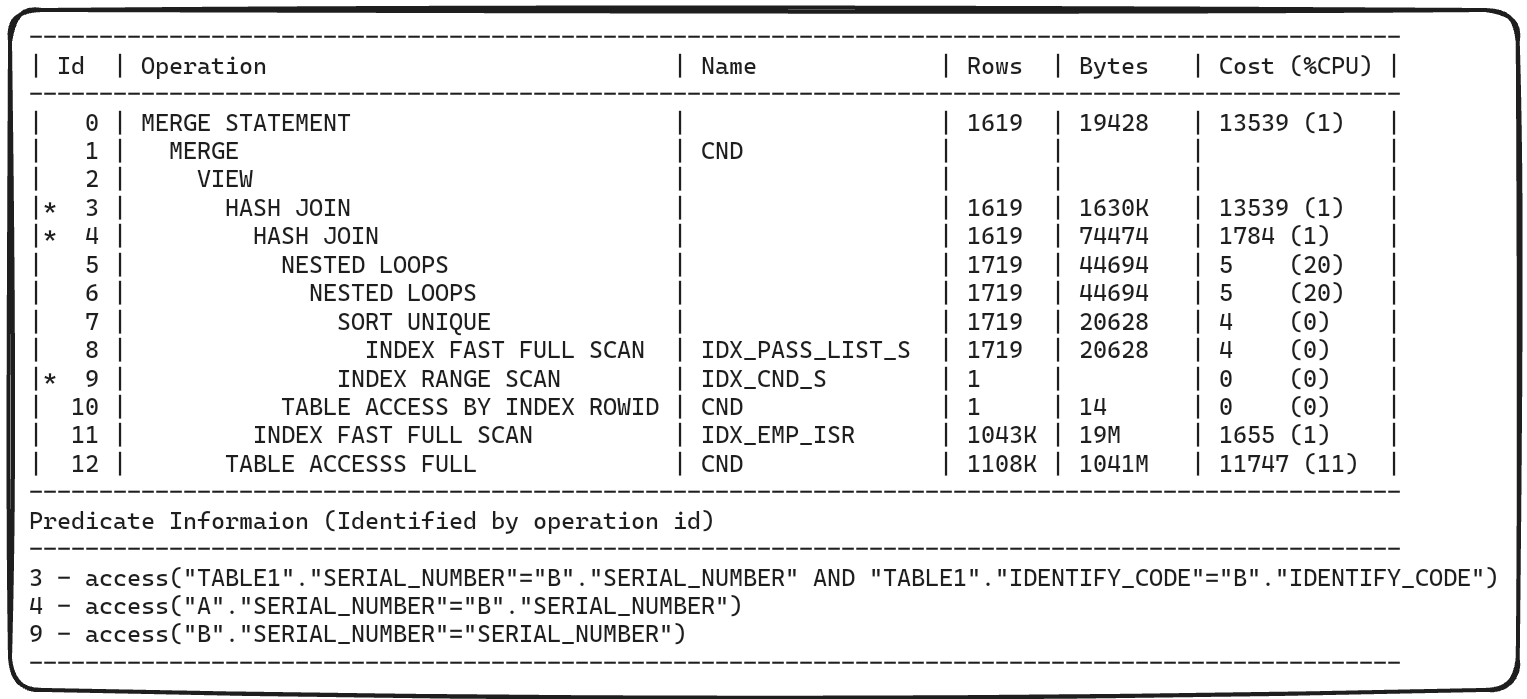
실행 계획의 ID를 기준으로 실행 순서대로 살펴보겠습니다. (이해하기 쉽게 설명 중 각 테이블의 alias도 함께 작성했습니다.)
- ID 8: 인덱스를 이용하여 pass_list의 serial_number 조회
- ID 7: 구한 serial_number를 중복 제거 정렬
- ID 9: 앞서 구한 결과와 일치하는 cnd b의 serial_number 조회
- ID 10: 9번의 조회 결과를 이용하여 cnd 테이블의 실제 데이터에 액세스
- ID 6, 11, 5: Query Transformer가 SQL 구문을 변경했을 것으로 예상되어 정확한 조인 조건을 알 수 없으나
인라인 뷰를 완성하기 위헤 Nested Loop 조인을 수행하고, Outer Table인 emp a에 대해 인덱스 풀 스캔 - ID 4: 필터링 된 cnd b를 Build Table로 설정하여 b.serial_number 조인 키를 해시화하고 PGA의 해시 태이블에 저장한 후,
cnd a를 Probe Table로 설정하여 해시 함수를 통해 해시 테이블과 조인 - ID 12: Hash Join의 드라이빙 테이블로 선정된 emp tab1을 풀 액세스함
- ID 3: 풀 액세스 한 emp tab1의 데이터를 tab1.serial_number 컬럼과 tab1.identify_code를 조인 키로 해시 테이블에 올린 후 완성된 tab2 인라인 뷰와 Hash Join함
Hash Join Hint(/*+ USE_HASH(tab1 tab2) */)를 사용한 SQL 구문의 Cost는 13539 cost로 측정되었습니다. Operation 중 가장 높은 Cost를 최종 Cost로 측정하므로 3번 ID의 Hash Join Operation가 최종 Cost로 측정되었음을 알 수 있습니다.
13539라는 Cost값이 문제가 있는 정도로 큰지 아닌지 지금은 잘 모르겠습니다. 문제를 분석하기 전에 Hash Join Hint가 없을 때의 실행 계획을 먼저 살펴볼까요?
1
2
3
4
5
6
7
8
9
10
11
MERGE
INTO emp tab1
USING (
SELECT a.identify_code, a.serial_number, b.hiredate
FROM cnd a, emp b
WHERE a.serial_number = b.serial_number
AND b.serial_number IN (SELECT serial_number FROM pass_list)
) tab2
ON (tab1.serial_number = tab2.serial_number AND tab1.identify_code = tab2. identify_code)
WHEN MATCHED THEN
UPDATE SET tab1.hiredate = tab2.hiredate;
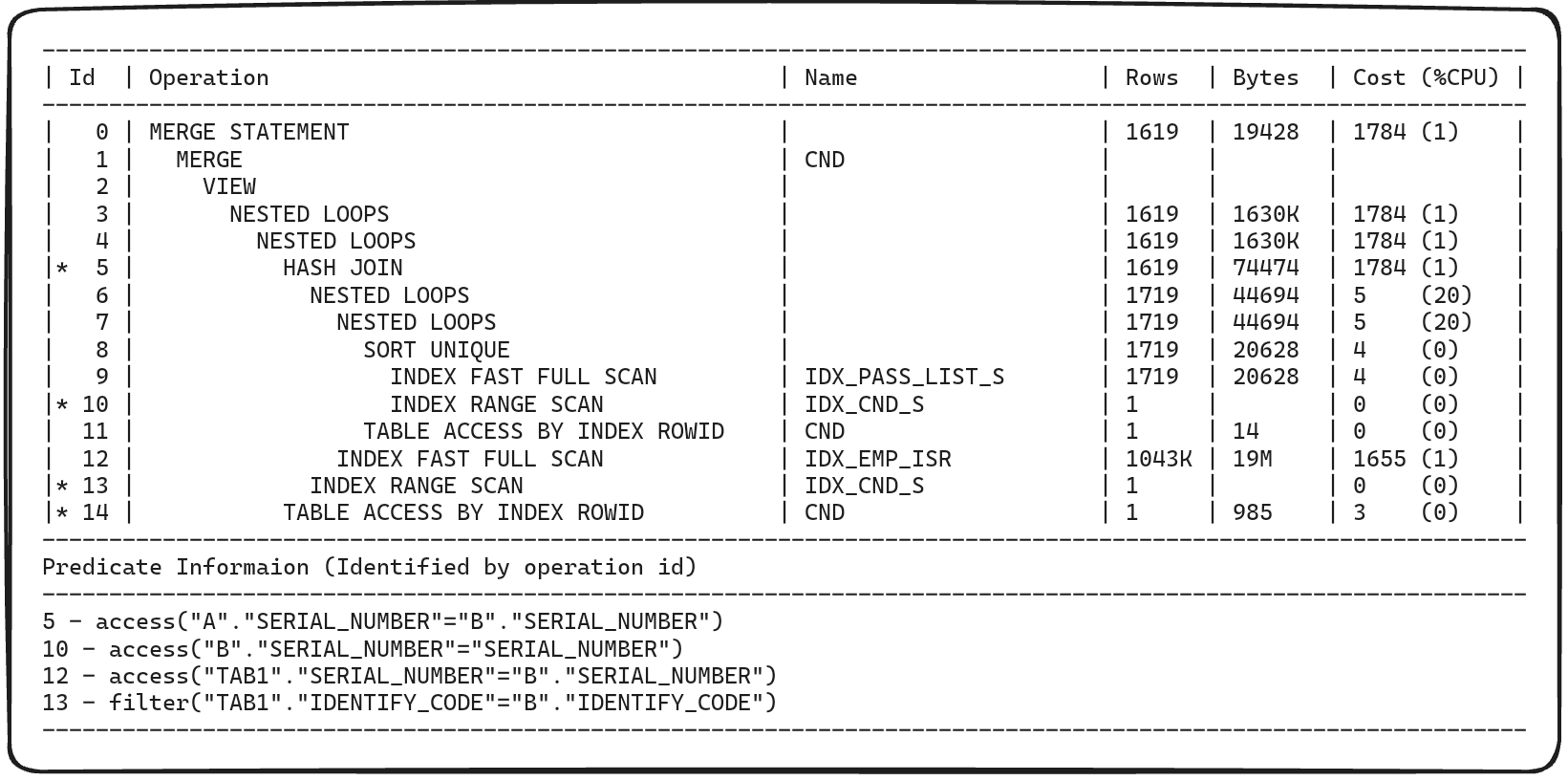
위에서 분석해 본 Hash Join Hint를 사용한 SQL 구문의 실행 계획과 다른 점은 맨 마지막 프로세싱 과정인 Hash Join이 두 번의 Nested Loop Join으로 바뀌었다는 것 말고는 없습니다.
그런데 이번 실행 계획의 Cost는 1784 cost가 나왔네요. 무려 Cost가 7.5배나 차이가 납니다! Hash Join Hint를 사용할 때의 Cost가 굉장히 높게 측정됐다는 걸 알게 되었습니다. 축하드립니다!!!
그럼 Hash Join Hint를 사용했을 때 어떤 문제가 생긴걸까요? Build Table로 설정한 emp tab1 테이블은 총 로우 수가 17k 정도 되는 대용량 테이블입니다. 권한 이슈로 인해 PGA 영역의 메모리 확인은 불가능하지만 In-Memory 조인 방식 사용이 불가능해 임시 디스크를 사용했을 것으로 추측됩니다. 또한 조인 키로 사용되고 있는 serial_number 컬럼은 distinct한 기본키입니다. 따라서 Cost 측정의 주요 항목 중 하나인 Cardinality 또한 17k의 값을 가지며 Cost 측정에 큰 영향을 미쳤을 것으로 예상됩니다.
그렇다면 Hash Join Hint 사용 시 각 테이블의 순서를 바꿔볼까요?
1
2
3
4
5
6
7
8
9
10
SELECT /*+ ORDERED USE_HASH(tab2 tab1) */
tab1.hiredate, tab2.hiredate
FROM (
SELECT b.identify_code, b.serial_number, a.hiredate
FROM cnd a, emp b
WHERE a.serial_number = b.serial_number
AND b.serial_number IN (SELECT serial_number FROM pass_list)
) tab2, emp tab1
WHERE tab1.serial_number = tab2.serial_number
AND tab1.identify_code = tab2. identify_code;
상대적으로 작은 인라인 뷰 테이블이 Build Table로 선정되어 실행 계획의 Cost가 9k까지 줄어든 것을 확인할 수 있었습니다.
4. Conclusion
실행 계획을 분석한 결과 Hash Join Hint가 SQL 구문에서 문제를 일으킨 이유를 이렇게 정리해볼 수 있을 것 같습니다.
- 해시 조인 사용을 위한 Build Table 및 Probe Table이 적절하게 선정되지 않았다.
- 조인을 수행하는 두 테이블 모두 해시 영역에 올리기에는 데이터가 너무 많아 디스크의 임시 공간을 사용하게 되면서 성능 저하가 발생하였다.
위의 문제에 따른 결론이라고 한다면.. Optimizer를 신뢰하자 정도가 될까요? 농담말고 제대로 결론을 내자면 다음과 같이 얘기해 볼 수 있겠습니다.
Join Hint를 사용하기 이전에 테이블 구조 및 Optimizer의 실행 계획에 대해 정확하게 분석한 후에 생각한 의도대로 실행 계획이 세워지지 않았다면 Join Hint를 통해 실행 계획을 의도에 맞게 안내하자.
지금까지 Oracle에서 제공하는 SQL Tuning Guide 및 기타 유용한 정보들을 찾아보며 개인적으로 생각하기에 가장 가까운 해석을 작성해봤습니다. 성능 저하 원인에 대해 분석하기 위해 주어진 DB 권한도 충분치 않았고, Oracle DB에 대한 지식이 부족한 상태로 원인을 분석하였기 때문에 정확한 분석 결과는 아닐 수 있지만 SQL Processing, Optimizer 및 SQL 실행 계획의 흐름을 알아가는데 이 글이 도움이 되기를 바랍니다.